
Publications
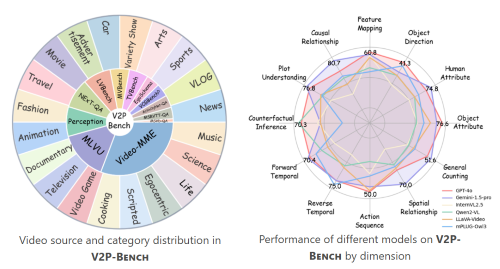
V2P-Bench: Evaluating Video-Language Understanding with Visual Prompts for Better Human-Model Interaction
Yiming Zhao, Yu Zeng, Yukun Qi, YaoYang Liu, Lin Chen, Zehui Chen, Xikun Bao, Jie Zhao, Feng Zhao
ICLR, 2026
V2P-Bench is a comprehensive benchmark specifically designed to evaluate the video understanding capabilities of LVLMs in human-model interaction scenarios.

Magic Mirror: ID-Preserved Video Generation in Video Diffusion Transformers
Yuechen Zhang*, Yaoyang Liu*, Bin Xia, Bohao Peng, Zexin Yan, Eric Lo, Jiaya Jia
ICCV, 2025
MagicMirror is a video generation framework that preserves identity while producing high-quality, natural motion, achieving state-of-the-art results with minimal added parameters.
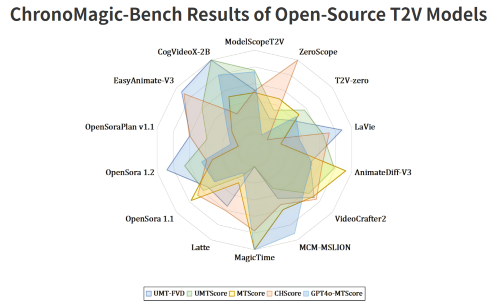
ChronoMagic-Bench: A Benchmark for Metamorphic Evaluation of Text-to-Time-lapse Video Generation
Shenghai Yuan, Jinfa Huang, Yongqi Xu, Yaoyang Liu, Shaofeng Zhang, Yujun Shi, Ruijie Zhu, Xinhua Cheng, Jiebo Luo, Li Yuan
NeurIPS D&B (Spotlight), 2024
ChronoMagic-Bench can reflect the physical prior capacity of Text-to-Video Generation Model.