
Posts by Collection
portfolio
publications
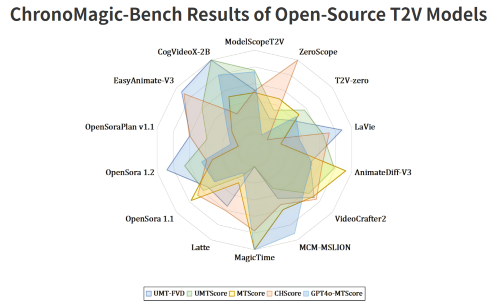
ChronoMagic-Bench: A Benchmark for Metamorphic Evaluation of Text-to-Time-lapse Video Generation
NeurIPS D&B (Spotlight), 2024
ChronoMagic-Bench can reflect the physical prior capacity of Text-to-Video Generation Model.

Magic Mirror: ID-Preserved Video Generation in Video Diffusion Transformers
ICCV, 2025
MagicMirror is a video generation framework that preserves identity while producing high-quality, natural motion, achieving state-of-the-art results with minimal added parameters.
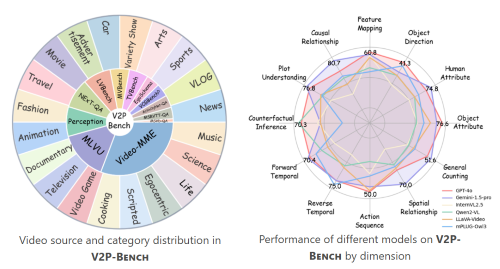
V2P-Bench: Evaluating Video-Language Understanding with Visual Prompts for Better Human-Model Interaction
ICLR, 2026
V2P-Bench is a comprehensive benchmark specifically designed to evaluate the video understanding capabilities of LVLMs in human-model interaction scenarios.
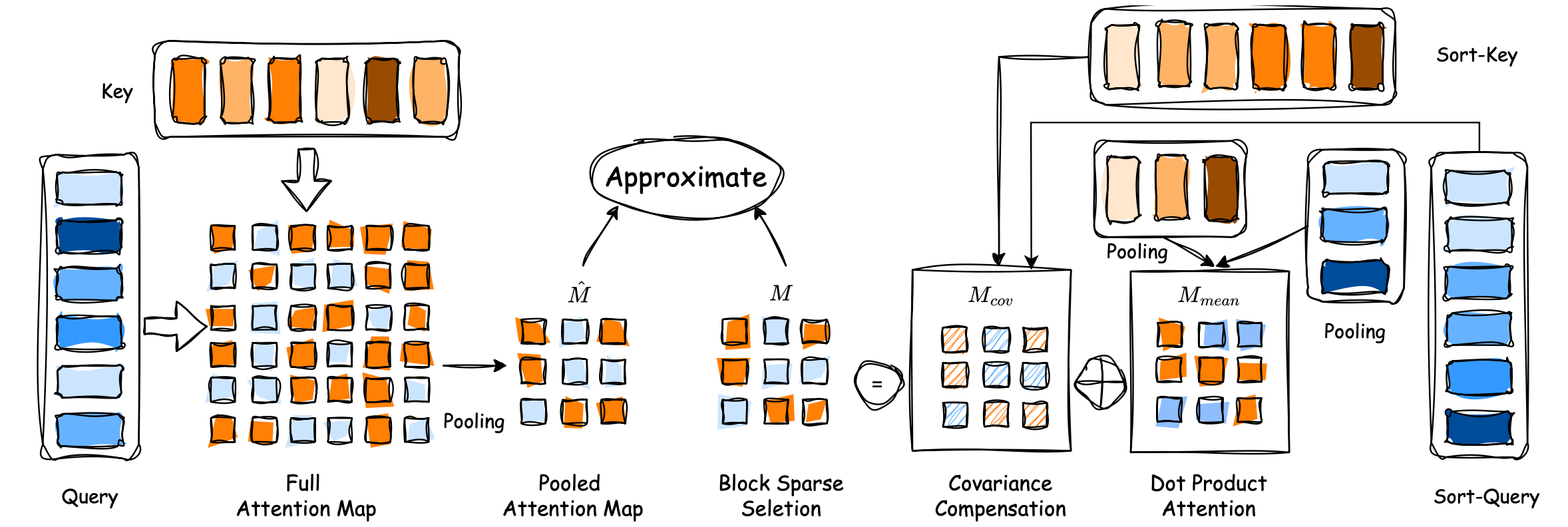
Efficient Long-Context Modeling in Diffusion Language Models via Block Approximate Sparse Attention
CVPR Findings 2026
We propose BA-Att, a block approximate sparse attention framework with pre-downsampling and covariance-compensated correction, achieving up to 6.95× speedup over FlashAttention at 50% sparsity across language, multimodal, and video generation models.

SwiftI2V: Efficient High-Resolution Image-to-Video Generation via Conditional Segment-wise Generation
Preprint 2026
We propose SwiftI2V, an efficient framework for high-resolution (2K) I2V generation that decouples motion modeling from detail synthesis via progressive segment-wise generation and bidirectional contextual interaction. SwiftI2V achieves performance comparable to end-to-end baselines while reducing total GPU-time by 202×, enabling practical 2K I2V on a single RTX 4090.